Visual Identification
This section describes general principles regarding the visual identification algorithm in 🦖.
Motivation
This algorithm was added to 🦖 because tracking based on kinematics alone can never guarantee perfect assignments. Even under ideal conditions. The reason for this is that whenever individuals are hidden for arbitrary amounts of time, potentially in the same position (i.e. overlapping or under some kind of cover), simple predictions as to the likely identity assignments will fail after they reemerge.
The only solution is to add another, idependent source of information - for which there are a few possibilities:
use size differences: not always possible, when similarly sized individuals are present
use physical marks: adding physical tags/information to animals in the “real world” is a frequently used method, and often works well. However, physical attachments can alter the behavior of individuals (e.g. due to the attachment process or differences in movement dynamics), and can thus be problematic.
Here, we use a third alternative: recognizing individuals by a process akin to face recognition (although more general). We take multiple pictures of each individual and teach an artificial neural network to differentiate between the animals. In the end we will be able to consistently assign the same number to each “physical” individual, independently of how it may look in any single image. Many examples/samples are required to cover most of the possible visual variation, making it very tedious to collect them manually - especially for large groups. This is why 🦖 employs an algorithm that allows, given certain preconditions, to do all this automatically.
The algorithm chooses a point in time when all known individuals are visible and separated at the same time. This provides a starting point for collecting a number of samples per “physical” individual. From there the samples per individual can be expanded per individual (in both directions of time) until it is lost - e.g. due to overlapping with another individual. Afterward, other such “global segments” (where all individuals are separated) can be added.
The following sections describe how to improve tracking data with the goal of applying the visual identification algorithm.
General procedure
The most important thing is that consecutive tracking sequences (see Timeline for how they are displayed) exist for each individual and are as long as possible - while avoiding misassignments. So you can relax parameters like track_max_speed and track_size_filter to lengthen tracklets, but make sure that this does not lead to unrecognized tracking errors. Tracking errors are generally “fine” for the identification algorithm, but evil lurks whenever identity switches occur in the middle of a consecutive segment - this would mean that the switch has not been recognized, as tracklets are ended whenever “risky business” is detected. So a non-detection like this hints at suboptimal tracking parameters.
Note
The current tracklets per individual are displayed on the top-left when the individual is selected (and when you’re in tracking view, see Keyboard shortcuts).
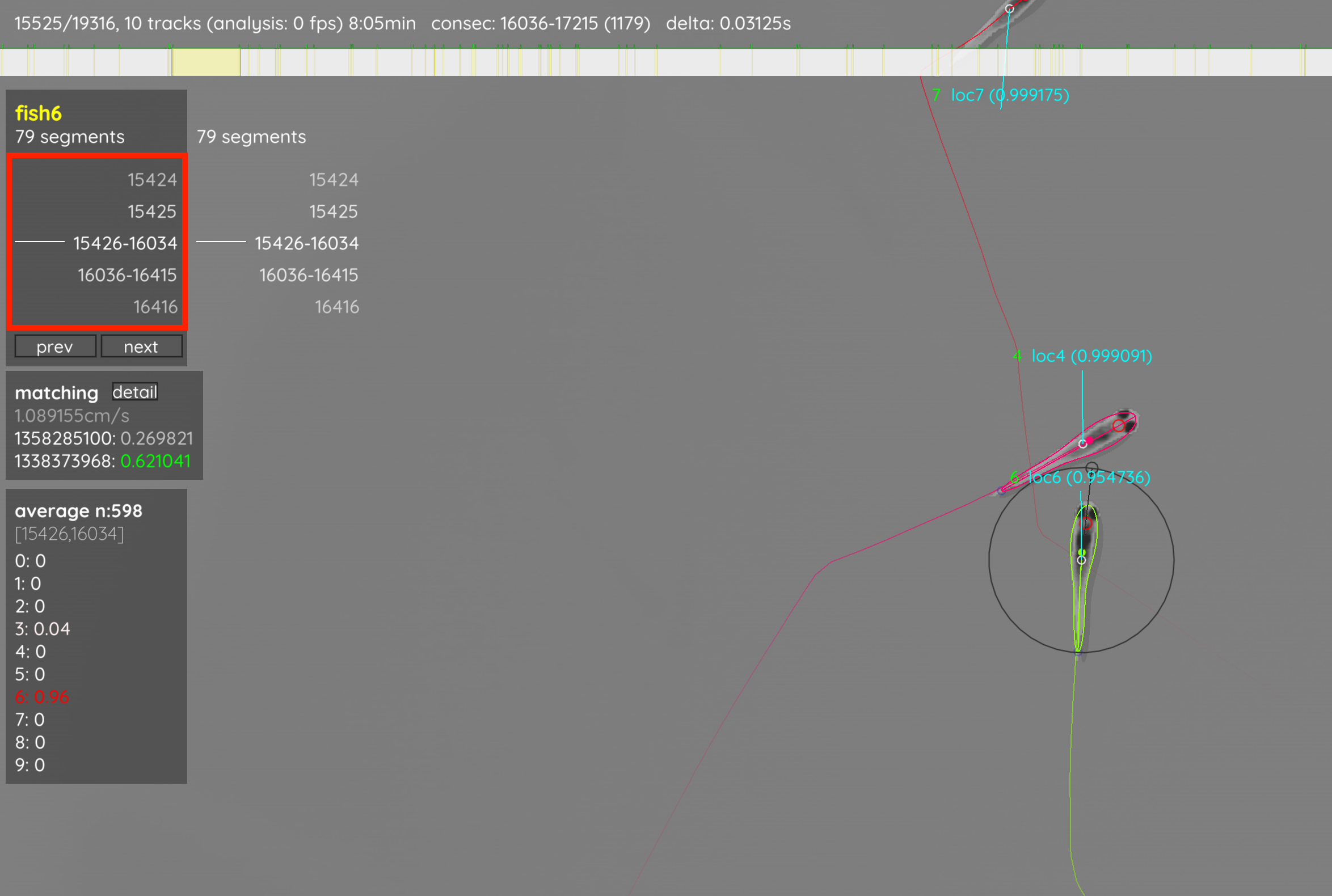
You also have to set a fixed number of individuals by setting track_max_individuals manually, or relying on the automatic detection. This value has to be either appended to the command-line, or saved in the video’s settings file to be applied before the program is started.
Once you are happy with the tracking results, click on menu -> visual identification. This gives you a short description that you should probably read. Now, click “Start”. Keep in mind that this will remove all previously added manual_matches and retrack the entire video - automatically applying the generated identity predicitions.
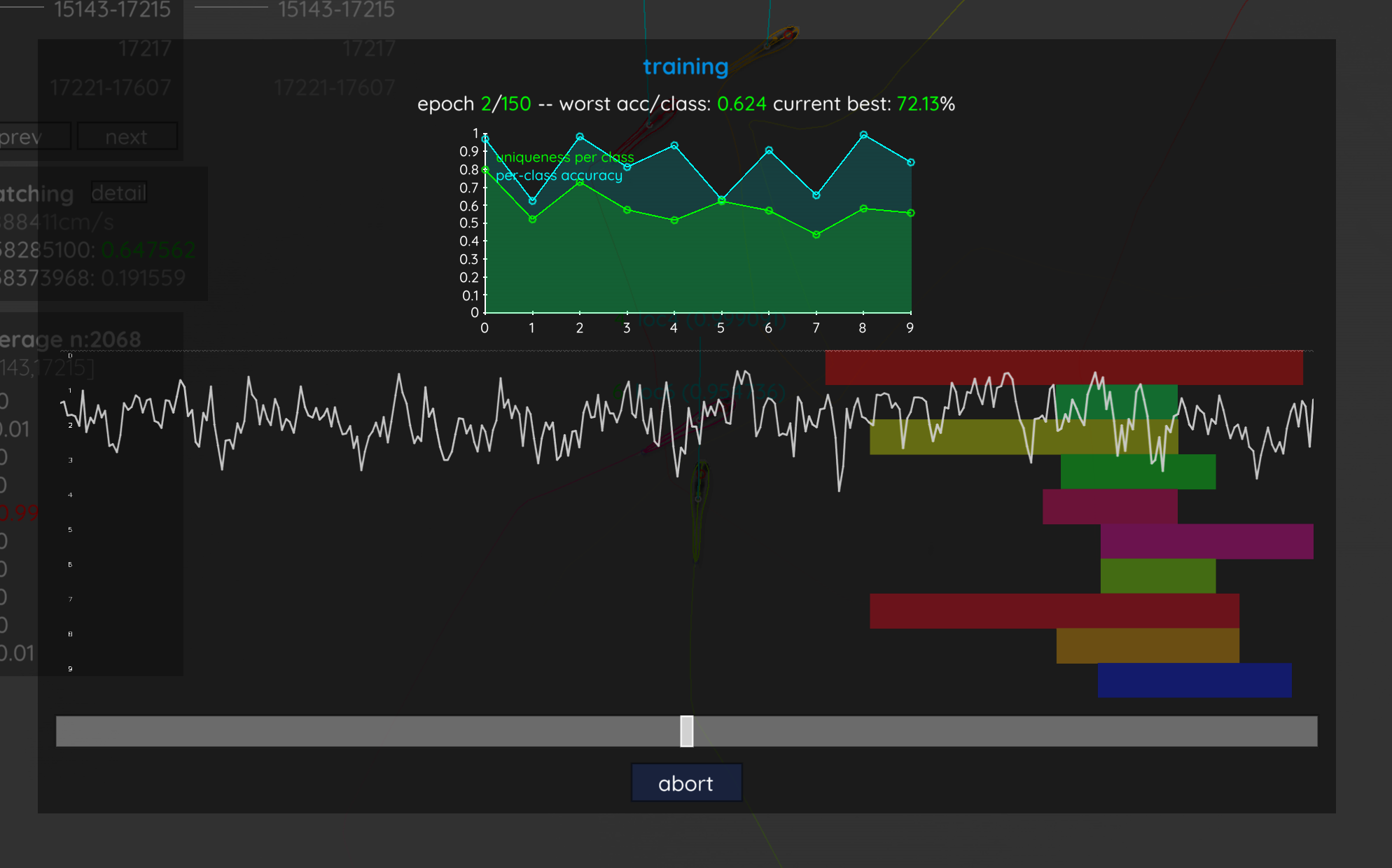
You now have to sit back and wait, or grab a coffee, while the algorithm tries to (starting at the consecutive segment that is highlighted green in the timeline) find samples for each individual until a uniqueness of at least accumulation_sufficient_uniqueness is achieved, or no more suitable segments can be found.
When training is over, the video will be retracked and now most numbers above the individuals should be green. You can also click on the display menu (bottom-left) and select “dataset”. This will show the current averaged prediction values per individual and quality measurements of the current consecutive segment. Check for misassignments and adjust parameters as required. Once you’re happy with your results, you can export the tracking data by pressing S, or apply the same parameter settings to other videos of the same batch (menu -> save config).
Common troubles
If the training takes really long, first check if TRex is using the correct graphics card (if any). This, once visual identification is started, will be visible on the bottom right of your screen, e.g. on an Apple M1 (but note that not all GPUs sport such a Metal name):

If this is correct, but you are experincing long training times with low uniqueness values (e.g. below chance), check again for tracking mistakes. Over 90% of such errors stem from tracking mistakes.
If you are experincing long training times, but high uniqueness values, instead the cause is likely a high number of samples per individual. You can cap this by setting gpu_max_sample_gb to a lower value (e.g. 0.5).
Another possibility is that individuals may not be visible in their entiretythe training samples. This can be adjusted by either downscaling them (individual_image_scale), or increasing the image size (individual_image_size). You can view these samples by setting visual_identification_save_images to true before starting the training process, and then opening the generated file in e.g. Python. It is called <output_dir>/<videoname>_validation_samples.npz.